
Share your love
Quick Steps To Install Apache Spark on Debian 12

In this guide, you will learn to Install Apache Spark on Debian 12, Access the Web UI, and also access the Spark and PySpark Shell from the Command line interface.
Apache Spark is an open-source big data distributed processing framework. It provides development APIs in Java, Scala, Python, and R. PySpark is the Python API for Apache Spark. With PySpark, you can perform real-time, large-scale data processing in a distributed environment using Python. Also, it provides a PySpark shell for interactively analyzing your data.
Now you can follow the rest of the article on the Orcacore website to get the easy steps to install Apache Spark on Debian 12.
Table of Contents
Quickly Install Apache Spark on Debian 12
Before you start the Spark setup on Debian 12, you must log in to your server as a non-root user with sudo privileges. To do this, you can check the Initial Server Setup with Debian 12.
Then, follow the steps below to install Apache Spark on Debian 12.
Step 1 – Install Java For Spark Setup on Debian 12
To install Apache Spark on Debian 12, you must have Java installed on your server. First, run the system update with the command below:
sudo apt updateThen, run the command below to install default Java on Debian 12:
sudo apt install default-jdk -yVerify the Java installation by checking its version:
java --versionIn your output, you will see:

Step 2 – Download and Install Apache Spark on Debian 12 From Source
Now you must install some required packages for Spark installation on your server. To do this, run the following command:
sudo apt install mlocate git scala -yThen, visit the Spark Downloads page and get the latest Apache Spark package by using the following wget command on Debian 12:
sudo wget https://dlcdn.apache.org/spark/spark-3.5.1/spark-3.5.1-bin-hadoop3.tgzNote: Hadoop is the foundation of your big data architecture. It’s responsible for storing and processing your data.
Once your download is completed, extract your downloaded file with the following command:
sudo tar xvf spark-3.5.1-bin-hadoop3.tgz
Then, you need to move your Spark file to the /opt directory. To do this, you can run the command below:
sudo mv spark-3.5.1-bin-hadoop3 /opt/sparkAt this point, you have learned to download and install Apache Spark on Debian 12. Now you must configure the Spark environment on your server.
Step 3 – Set Up Apache Spark Environment Path Variable on Debian 12
To set up the path variable for Apache spark, you need to open your bashrc file with your desired text editor like Vi Editor or Nano Editor:
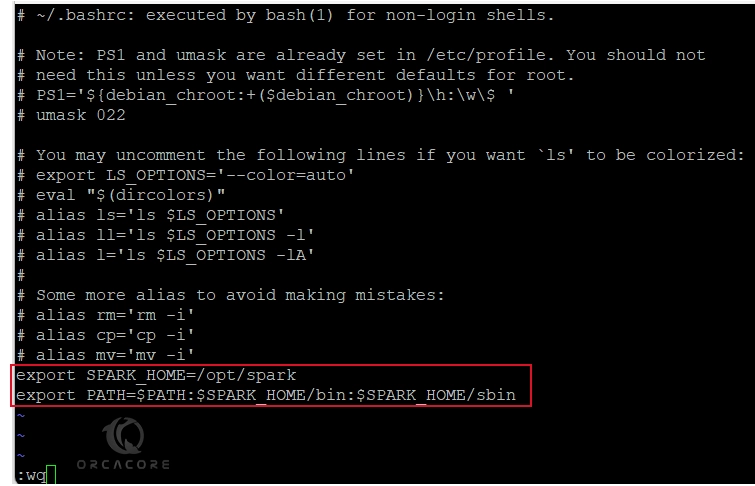
sudo vi ~/.bashrcAdd the following lines to the end of the file:
Note: Remember to set your Spark installation directory next to the Spark Home.
export SPARK_HOME=/opt/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbinOnce you are done, save and close the file.
Next, run the following command to apply the changes:
sudo source ~/.bashrcStep 4 – Access Apache Spark Shell on Debian 12 From CLI
At this point you have learned to install Apache Spark on Debian 12 and configure your environment path, you can easily access your Spark shell with the command below:
sudo spark-shellIn your output, you should see:
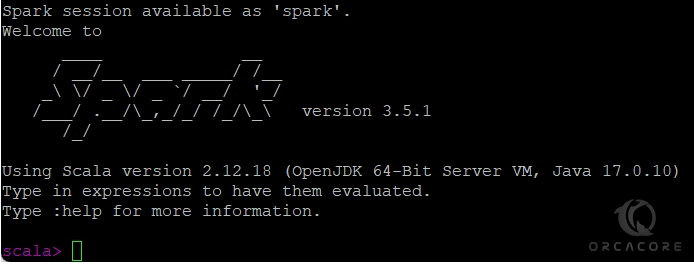
As you can see, the Spark shell started with Scala.
You can press CTRL+C to exit from the spark-shell.
Step 5 – Access PySpark Shell on Debian 12 From CLI
If you prefer to use Python instead of Scala, you can use PySpark. To run the PySpark shell, you can run the following command:
sudo pyspark
In your output, you will see:
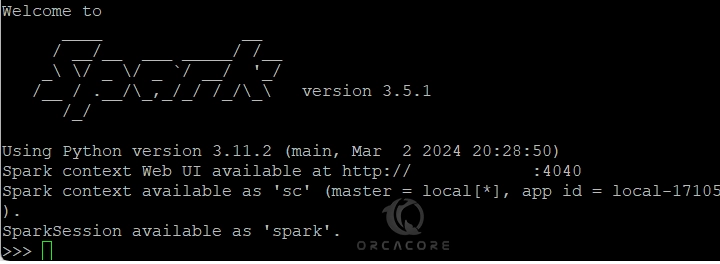
As you can see, the shell started with Python.
To exit from the PySpark shell, you can press CTRL+D.
Step 6 – Manage Spark Master Service on Debian 12
At this point, you can start your Apache Spark Master service on your server by using the following command:
sudo start-master.sh
Output
starting org.apache.spark.deploy.master.Master, logging to /opt/spark/logs/spark...By default, Apache Spark listens on port 8080. You can verify it using the following command:
sudo ss -tunelp | sudo grep 8080Output
tcp LISTEN 0 1 *:8080 *:* users:(("java",pid=68493,fd=268)) ino:804333 sk:6 cgroup:/user.slice/user-0.slice/session-173.scope v6only:0 <-> Start the Apache Spark worker process
At this point, you can start the Spark worker process by using the following command:
sudo start-worker.sh spark://your-server-ip:7077If you get a running process ID, stop it first, then, re-run the command.
Output
starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/logs/spark...Access Spark Master Web UI
At this point, you can access your Apache Spark Web UI by following the URL below:
http://your-server-ip:8080You should see the following screen:
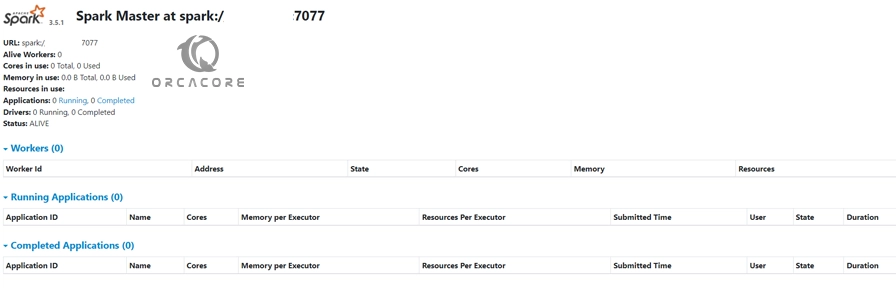
From there, you can get detailed information about your workers, running apps, and completed apps.
That’s it, you are done.
Conclusion To Apache Spark Setup on Debian 12
At this point, you have learned easy steps to install Apache Spark on Debian 12. As you can see, you can download the latest package from the source and configure the environment path to access the Spark and PySpark shells on your server. Then, you can easily manage your Spark master service and access the web UI dashboard.
Hope you enjoy using it. Also, you may like to read the following articles:
Install Scala 3 Using Terminal on Debian 12
Install Python 3.12 on Ubuntu and Debian Server


